
Our Amazon Sagemaker Processing job setup
At Snappet (we’re hiring!) we use Sagemaker Processing jobs to power most of our machine learning workflow. Sagemaker Processing jobs create our data, train our models, and hypertune our parameters.
I usually blog about things that I’ve learned and I think that this architecture is interesting enough to share and show you how it works.
As of writing this, most of jobs start from Jupyter notebooks, but we are in the process of turning these individual processing jobs into robust ML pipelines using Sagemaker Pipelines.
1. Creating the processing job
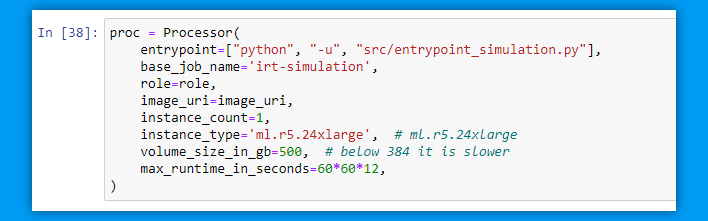
The first step in this whole process is creating the processing job.
We pass the input path (input_path), output path (output_path), and the arguments (foo) to the processing job and turn the arguments into a stringified list that Sagemaker understands.
args = {
'input_path': '/opt/ml/processing/input',
'output_path': '/opt/ml/processing/output',
'foo': 'bar',
}
args_list = []
_ = [args_list.extend([f"--{key}", value]) for key, value in args.items()]
Creating a processing job is as easy as importing the Processor and specifying an entrypoint (entrypoint) and a docker image uri (image_uri). For brevity I ommitted some of the other parameters.
from sagemaker.processing import Processor
proc = Processor(
entrypoint=["python", "-u", "src/entrypoint.py"],
image_uri=image_uri, # docker image pushed to ECR
...
)
2. Running the processing job
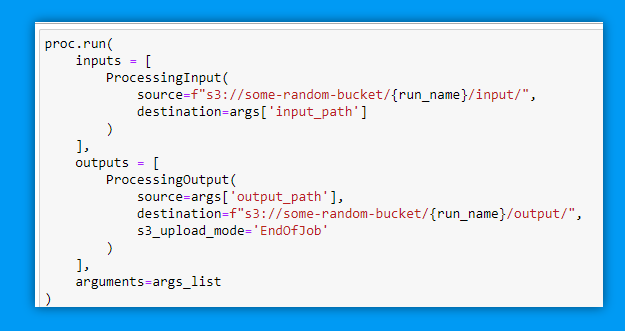
The second step after creating the job, is running it. For this we use
ProcessingInput and ProcessingOutput.
from sagemaker.processing import ProcessingInput, ProcessingOutput
proc.run(
inputs = [
ProcessingInput(
source=f"s3://{model_name}/{run_name}/input/",
destination=args['input_path']
)
],
outputs = [
ProcessingOutput(
source=args['output_path'],
destination=f"s3://{model_name}/{run_name}/output/",
s3_upload_mode='EndOfJob'
)
],
arguments=args_list
)
ProcessingInput allows us to download the data to the input_path and ProcessingOutput allows us to upload the results to the output_path. For example, input data could be the training data, and the output data could be the model weights.
3. The entrypoint
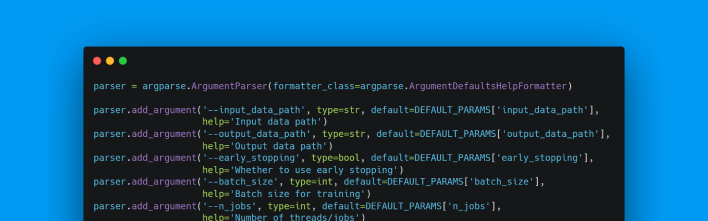
Notice that the processing job starts with the entrypoint. The entrypoint is the piece of code that defines how the program is ran, in other words, it is the interface of the program.
We believe that it is important to write software that has a strong and clear interface. Because this turns the code into a black box, something you can run by just looking at the entrypoint without worrying about the implementation.
Most of our entrypoints simply parse some arguments and look something like this:
if __name__ == '__main__':
parser = argparse.ArgumentParser(...)
parser.add_argument('--input_path', type=str, default='/opt/ml/processing/input/',
help='path to save input data to ')
parser.add_argument('--output_path', type=str, default='/opt/ml/processing/output/',
help='path to save output data to')
parser.add_argument('--foo', type=str, default='bar',
help="all other parameters")
args, _ = parser.parse_known_args()
param_dict = copy.copy(vars(args))
logging.info(f"Using arguments {json.dumps(param_dict, indent=2)}")
# Init
preprocessing_handler = PreprocessingHandler(
foo=param_dict["bar"],
)
# Run
preprocessing_handler.run(
input_path=param_dict["input_path"],
output_path=param_dict['output_path']
)
4. Wrapping it up in a nice docker

Nice, but how do you productize this? For this we use Docker. Our docker
files are quite basic, but we clearly separate the source code from the
entrypoints, and we use poetry as our package manager.
FROM python:3.8
WORKDIR "/opt"
# Dependencies
COPY poetry.lock .
COPY pyproject.toml .
RUN pip install poetry
RUN poetry config virtualenvs.create false
RUN poetry install --no-dev
# Entrypoints
COPY /entrypoints/ /opt/src/
# Core
COPY /src/ /opt/src/
# Git
RUN echo "SOURCE_COMMIT: $SOURCE_COMMIT"
# Entrypoint (doesn't do anything)
ENTRYPOINT ["python", "-u", "src/entrypoint.py"]
Using custom build scripts we build, tag, and finally push the docker images to our image repository, for which we use Amazon Elastic Container Registry (ECR).
Remember the image_uri that we passed as a parameter when creating the
processing job? That’s exactly the uri of this image that we push to the ECR.
This struck me in the beginning as a little bit weird, but ENTRYPOINT in the last line of the dockerfile actually gets overwritten by the Sagemaker’s entrypoint and thus is effectively useless.
Conclusion
So, that’s it! That is the rough structure that our pipelines follow at the moment. This structure is serving us quite well, but of course we are always improving it and currently we are in the processing of automating these using Sagemaker Pipelines which is another super interesting topic I should probably also cover some day!
To recap:
- We use Sagemaker Processing jobs to run dockers from our Amazon ECR
- Data comes in through
ProcessingInputand out throughProcessingOutputvia s3 - A well-defined
ENTRYPOINTin the form of anargparsespecifies the API of the program



Comments