
Regex For Noobs (like me!) - An Illustrated Guide
This blog post is an illustrated guide to regex and aims to provide a gentle introduction for people who never have fiddled with regex, want to, but are kind of intimidated by the whole thing.
In other words, welcome to …

For most people without a formal CS education, regular expressions (regex) can come off as something that only the most hardcore unix programmers would dare to touch.
A good regex can seem like magic, but remember this: any technology sufficiently advanced enough is indistinguishable from magic. So, let’s peel away at the magic of regex and see what’s underneath!
If you understand regex it suddenly becomes this super fast and powerful tool … but you first need to understand it, and honestly I find it a bit intimidating for newcomers!
Let’s start with the basics. What are regular expressions (regex) and what are they used for?
Regex for noobs
At its core, a regular expression is a sequence of characters defining a search pattern.
Regex is often used in tools like grep to find patterns in longer strings of text.
Consider a file cat.txt
cat
cat2
dog
If we use the regex cat to search for matches we find the following matches.
cat
cat2
(Note for the hardcore powerusers: In this post I’m going to conflate the terms regex and the tools that use regex such as grep. This is technically wrong, I am aware of this.)
Regex works on characters, not words
One important thing that can not be emphasized enough is this: regex works on characters, not words. Concatenation is implied.
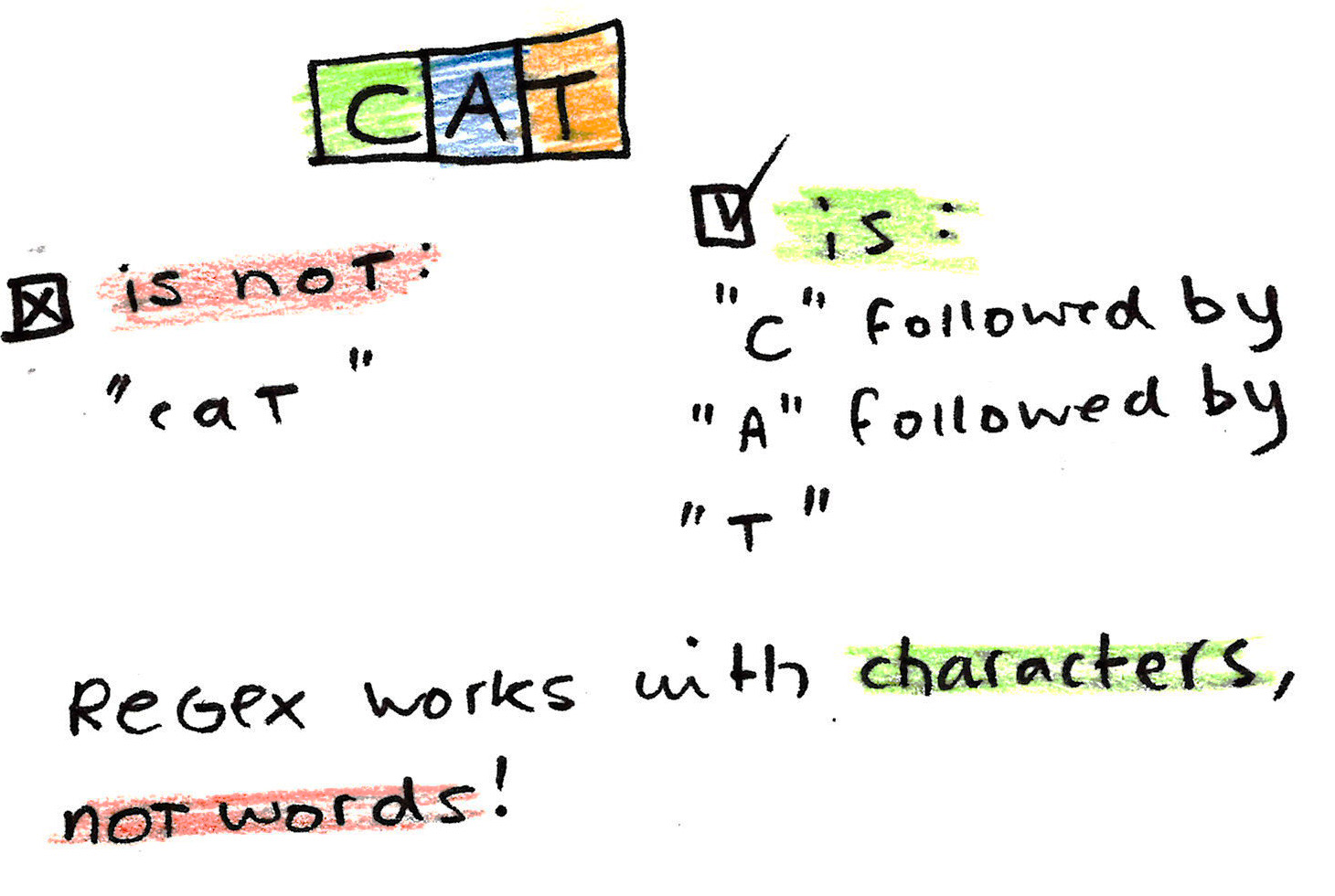
If we search using regex for the pattern cat, we are
not looking for the word “cat”, but we are looking for c followed by
a followed by t.
The dot and the asterisk
The most basic characters are the single characters, like a, b,
c, etc. Now let’s introduce two special guests.
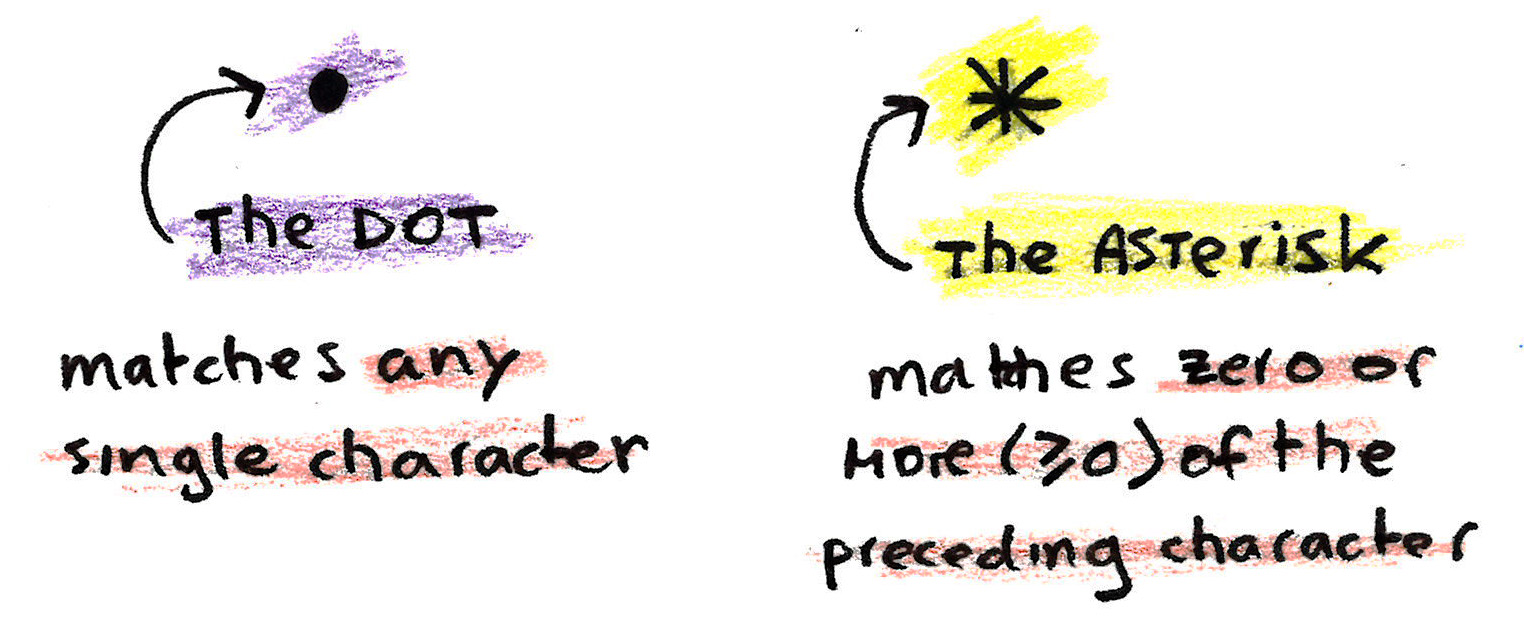
The . (dot) character matches any single character. For example, if we
search for c.t we would match anything ranging from cat to c0t
or cAt, we would match any single c followed by any character
followed by a single t.
The * (asterisk) character is a bit more difficult. It modifies the
character preceding it and then matches zero or more characters of
that. Yes, read that again, zero or more characters. For example,
cat* would match cat, catt, cattttt but also ca.
The cat ate my homework
Imagine we read in a file line by line and the first line is as follows.
The cat ate my homework.
Let’s look at how we would match the pattern cat in this line.
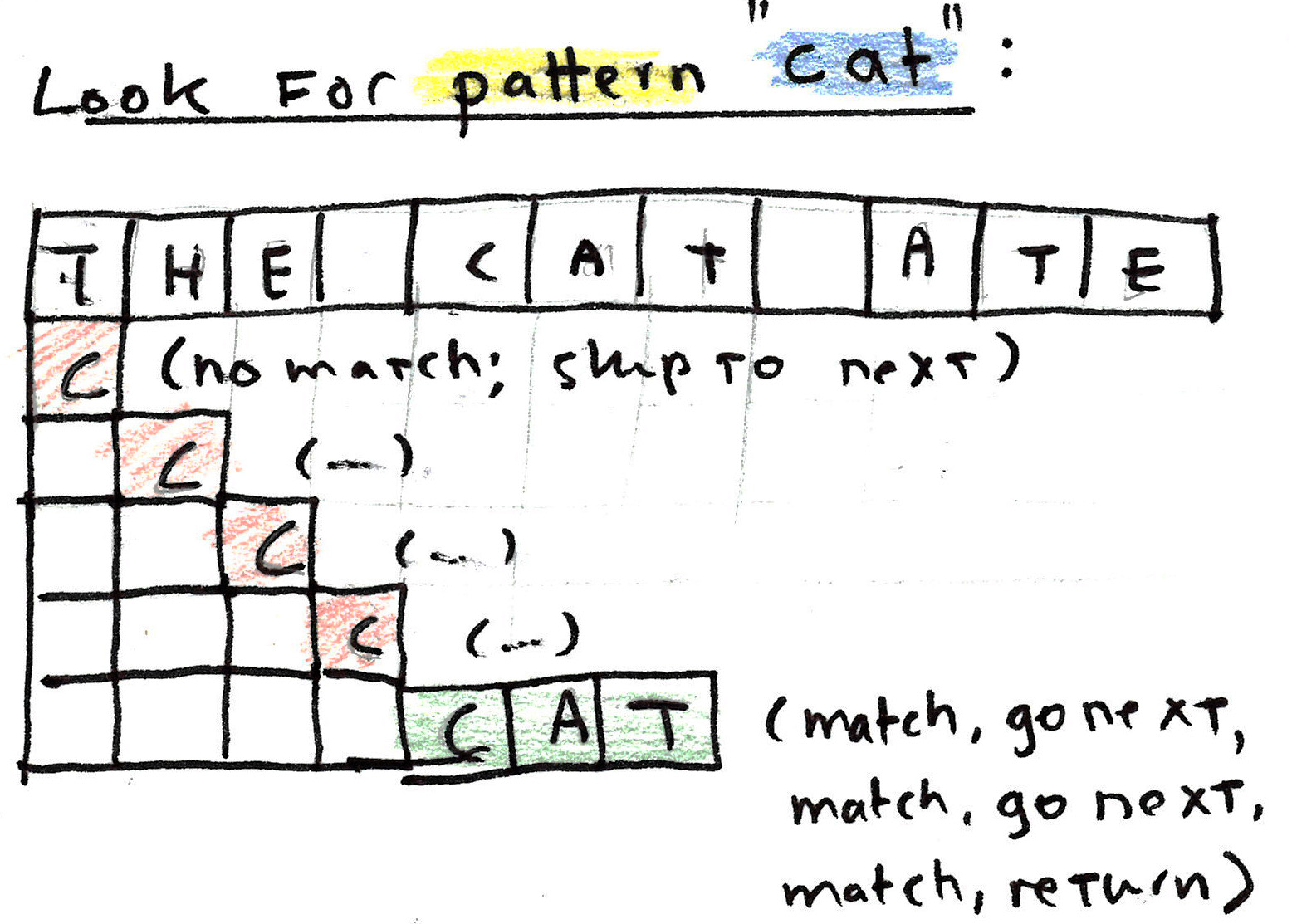
We start with matching the first character of the pattern to the first character in the sentence.
If we don’t find a match we skip to the next character in the line and start from the first character of the pattern.
If we do find a match we go to the next character in both the pattern and the line and repeat this process. When we find a match for the whole pattern we return the line in which we find a match.
That’s it! That’s what regex is most often used for at its most basic level, to find a smaller search pattern in a larger string.
So far we’ve gone over what regex is and two of the special
characters, the . (dot) and the * (asterisk), but wait, there’s
more.
The regex trifecta
Zooming out a little bit, the parts of a regex can consist of three different components:
- Anchors
- Character sets
- Modifiers
These three make up the … regex trifecta!
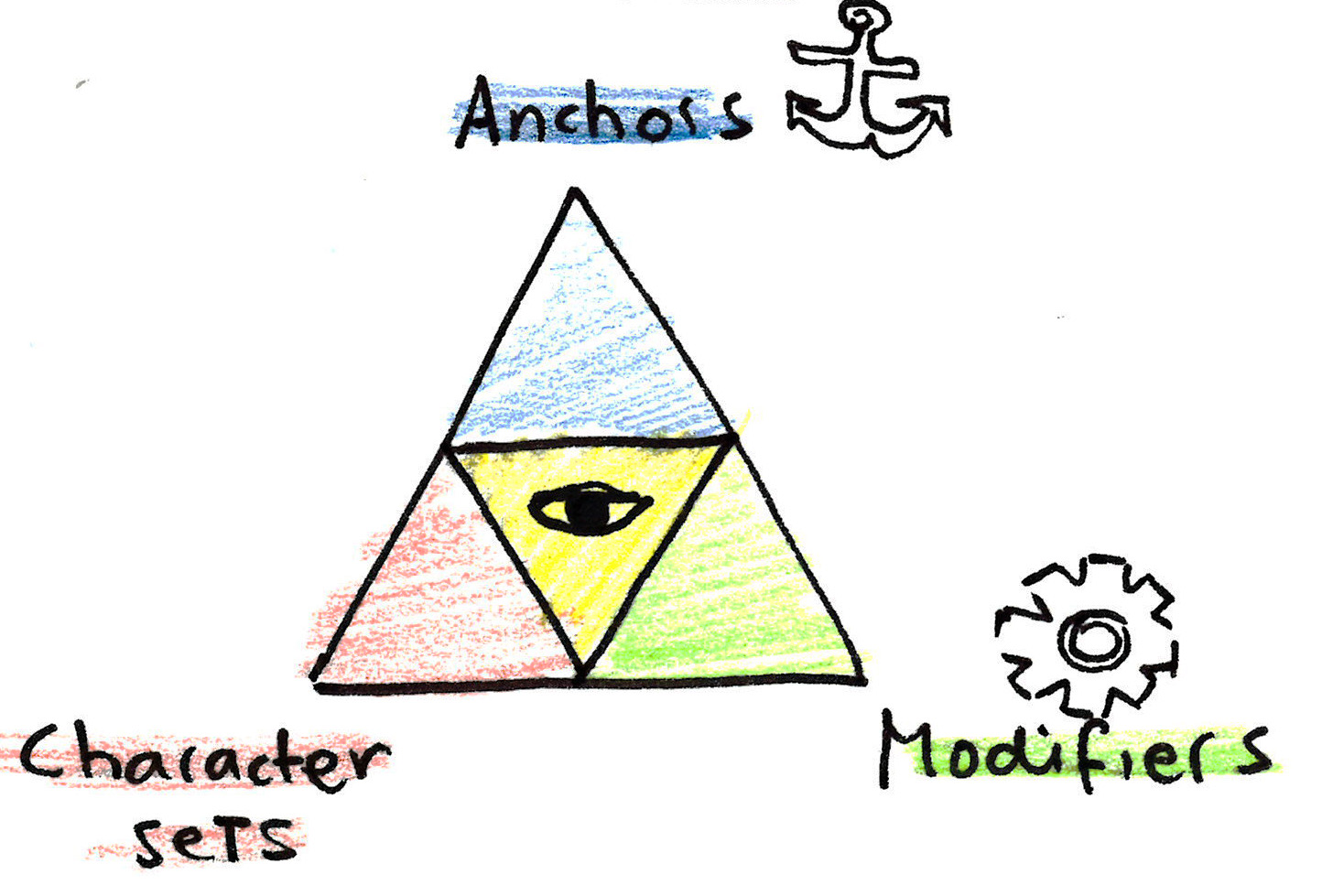
Let’s start with the first part of the trifecta: anchors!
Anchors

Anchors specify the position of the pattern with respect to the line. These are the two most important anchors:
- The
^(caret) fixes your pattern to the beginning of the line. For example the pattern^1matches any line starting with a1. - The
$(dollar) fixes your pattern to the end of the sentence. For example,9$matches any line ending with a9.
Note that in both cases the pattern has to be respectively first and
last in the pattern. ^1 matches a 1 at the start of a line but
1^ matches a 1 followed by a ^. Similarly, 1$ matches lines
ending with a 1 but $1 matches a dollar sign followed by a 1
anywhere on the line.
On to the second part of the trifecta: character sets!
Character sets
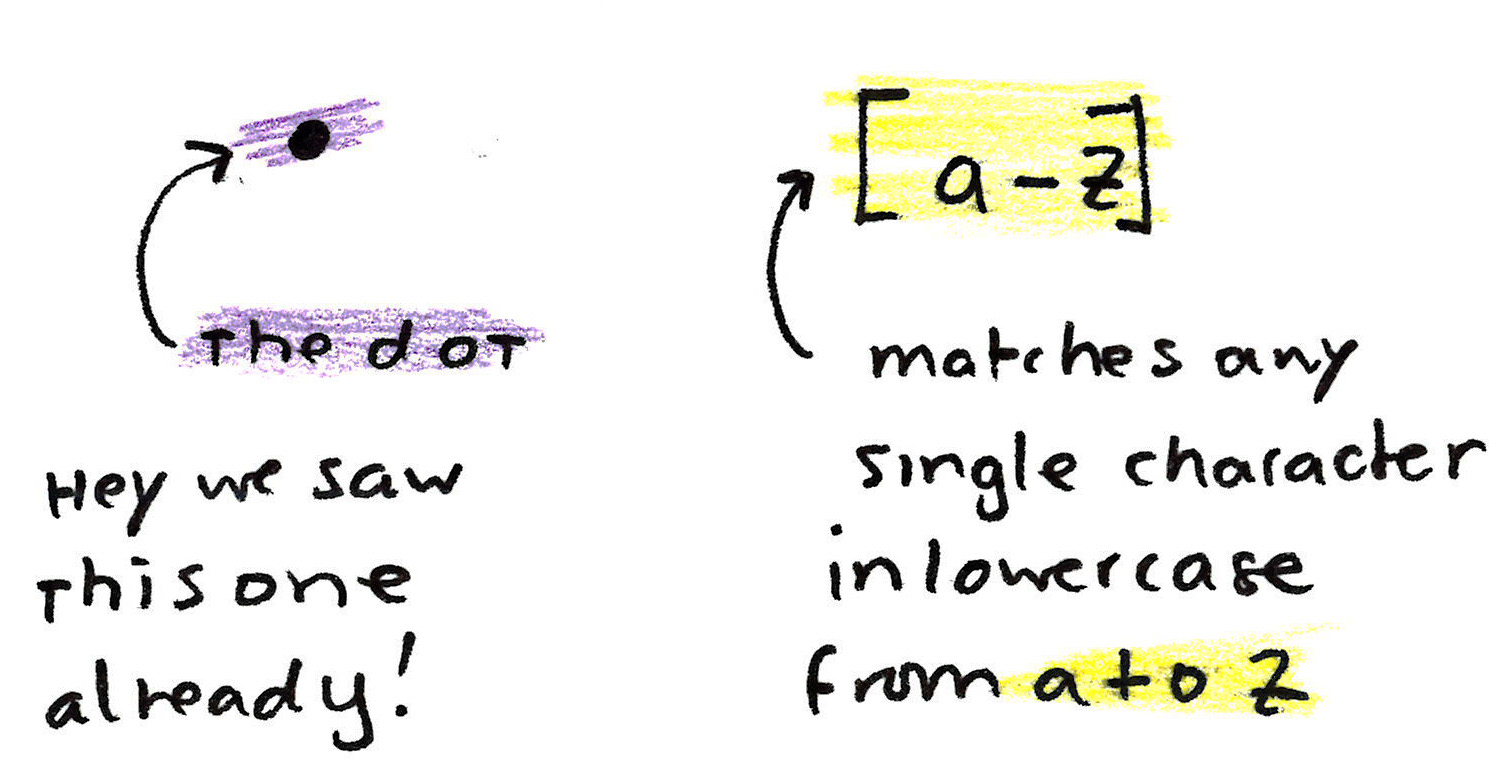
The second part of the trifecta: character sets. Character sets are
the bread and butter of regex. A single character, say a, is the
most atomic character set (a set of one element). But we can do crazy
stuff with regex like [0-9] which matches any single digit, or if
you recall what * does we can make the pattern [0-9][0-9]* (what
this pattern matches is left as an exercise to the reader).
Some other important character sets:
[0-9]matches any single digit from0...9[a-z]matches any lowercase character[A-Z]matches any uppercase characer
We can also combine multiple sets:
[A-Za-z0-9]matches any uppercase and lowercase letter and single digit.
Finally, modifiers.
Modifiers
I don’t want to get too much into depth here, but we already came
across a modifier! The * (asterisk) is a modifier. A modifier
changes the meaning of the character preceding it. There are many
other modifiers but starting with * is a good start.
An actual example
Let’s quickly dump some text in a file
$ echo "The cat jumps long time \nThen we also have the fact that these are words.\n1234 this is a test post please ignore." >> grep.txt
This is what’s in the file now
$ cat grep.txt
The cat jumps long time
Then we also have the fact that these are words.
1234 this is a test post please ignore.
Let’s look for cat
$ grep "cat" grep.txt
The cat jumps long time
Let’s look for any line starting with a digit ^[0-9]
$ grep "^[0-9]" grep.txt
1234 this is a test post please ignore.
That’s it! You just used regular expressions. Awesome.
Summary
In this blog post we went over:
- Basic functionality of regex
- The three main components of regex: anchors, character sets, and modifiers.
- The
.(dot),*(asterisk),^(caret), and$(dollar sign). - Some character sets
[0-9],[a-z],[A-Z], and combinations.
The goal of this blog post was to make regex a bit more approachable by means of an illustrated introduction.
If you peel away at the technical difficulties what you end up with is a relatively simple but super powerful tool that will prove invaluable in any data scientists’ toolbelt.




Comments