
Writing better code using interfaces
One thing that I’ve learned recently and that has improved my coding significantly is writing code in terms of interfaces.
The famous dependency injection mantra states that you should: “depend on abstractions and not on implementations”.
If you don’t understand the underlying idea behind this mantra, then the statement itself is so vague and general that it is practically useless.
I want to give a nice example illustrating the idea underlying this mantra so that you have a better understanding of the underlying concept. Then, once you understand that, the mantra becomes incredibly powerful on its own.
For me, the main idea behind all this talk about interfaces boils down to the fact that you want to design for swappability. Design your code in such a way that the things that you want to swap out, are easy to swap out.
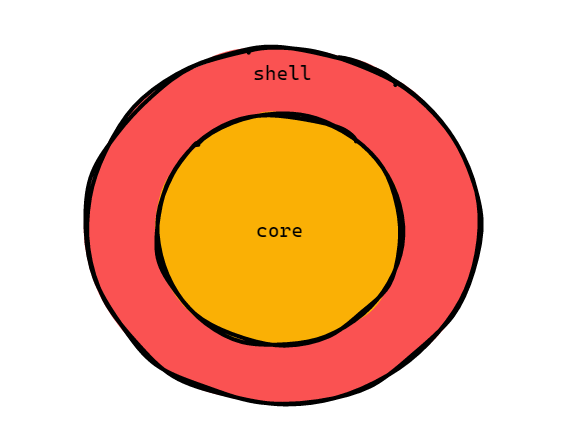
I’m going to lean into the functional core imperative shell idea here a bit. Your code can be thought of as an onion with two layers:
- The first layer we call the shell. For now, just think of it as the place where all data io happens
- The second layer we call the core is where all your core business logic happens, ideally this core is completely isolated from the outside world
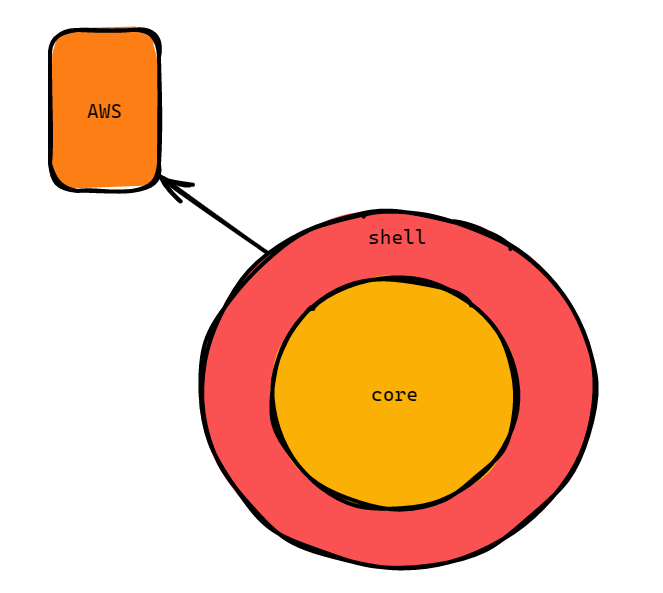
Imagine that, for some reason, we need to make a ping to AWS. We do not really want our core domain logic, the second layer, to be polluted with these external system calls.
How do we solve this?
By putting it on the outside of our program, by putting it in the shell so we can swap it out! Remember that we want to design for swappability.
When in production we need to be able to ping AWS. But during testing we should be able to swap out this service. We want to swap it out with a fake AWS that we control, for testing.
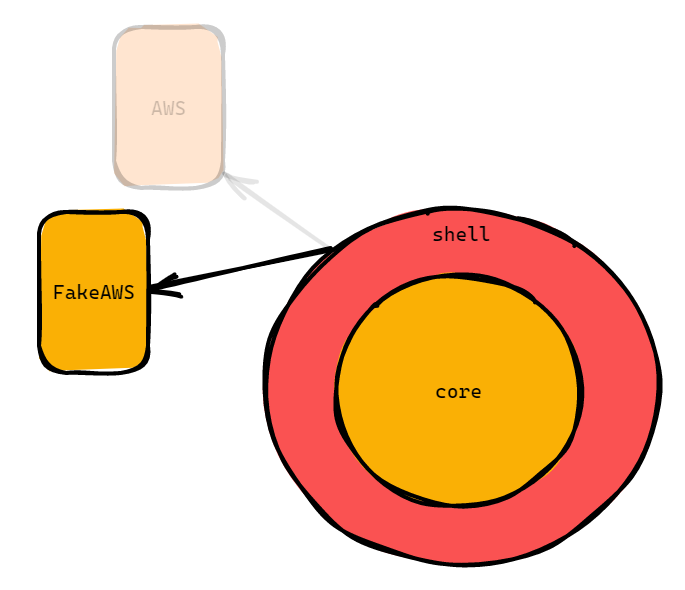
But this is pretty hard. How do we do this?
With interfaces!
This is exactly what is meant by depending on abstractions and not on implementations. Let me show you how.
Imagine that we are now on the inside of our core and we want to make a call to the AWS service. To do this, we define an interface that we call.
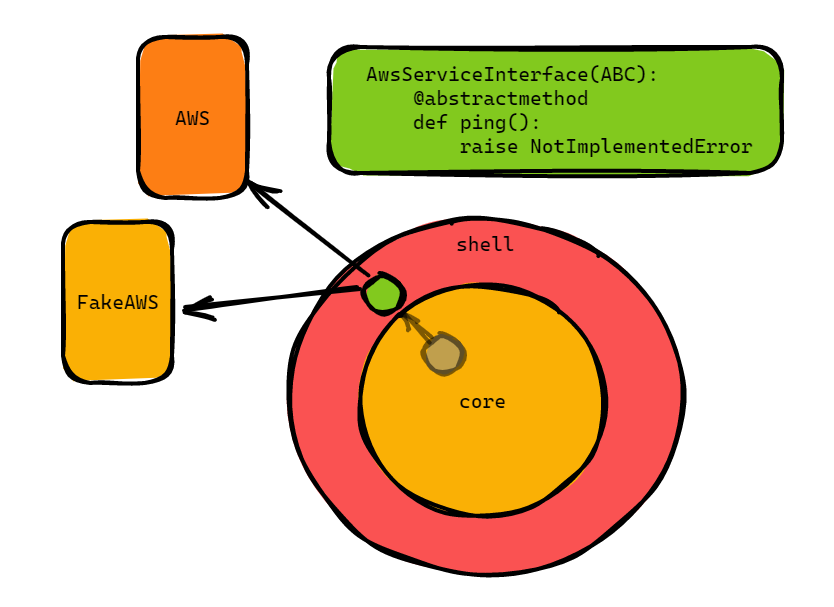
This means that we specify an interface, in this case the AwsServiceInterface. All that this does is that it tells us which functions we can call. Any implementation of this interface must at least implement the interface.
The real AWS implementation (not the interface!) calls a real boto function and hits production s3 like so:
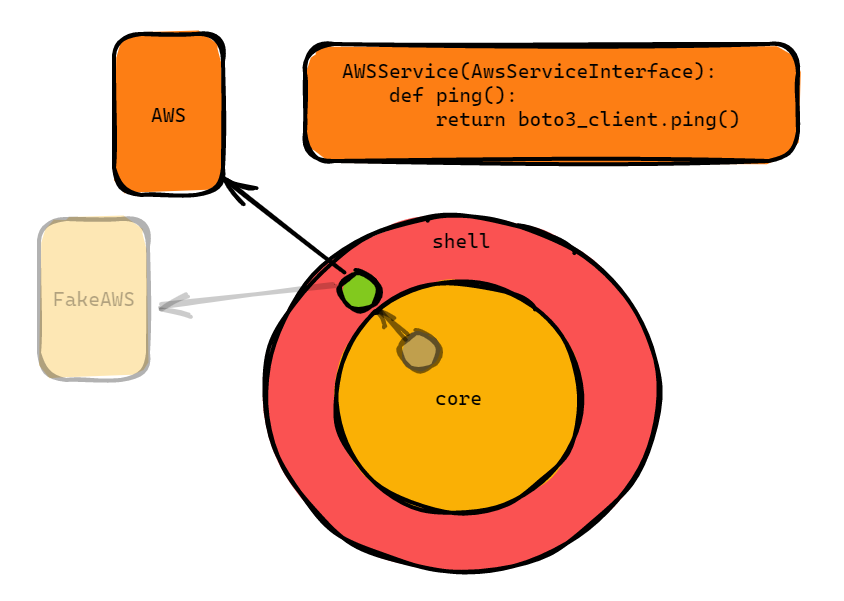
The fake that we use for testing, on the other hand, always returns 200 (or could hit some fake local setup).
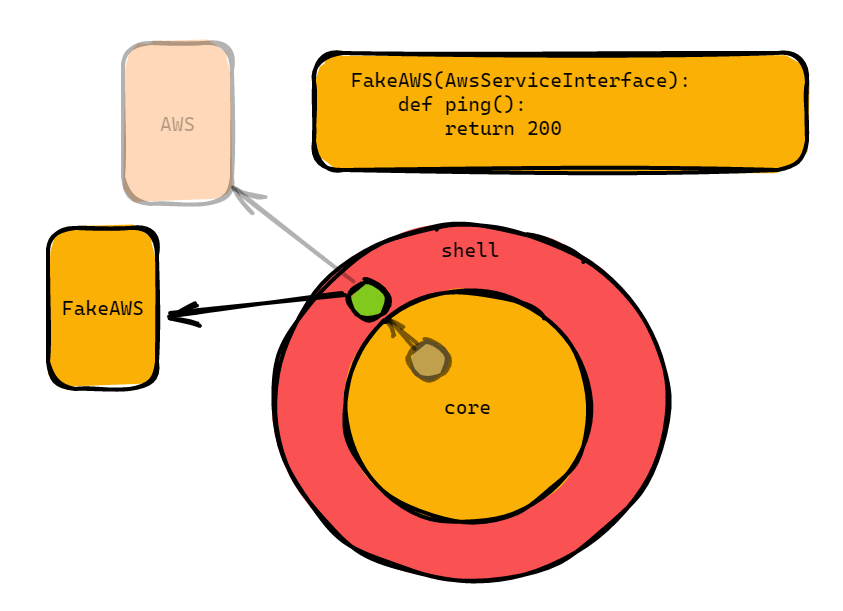
It really took me a while to get this but the beauty of this now is that grey, the core of our program, does not know anything about the outside world.
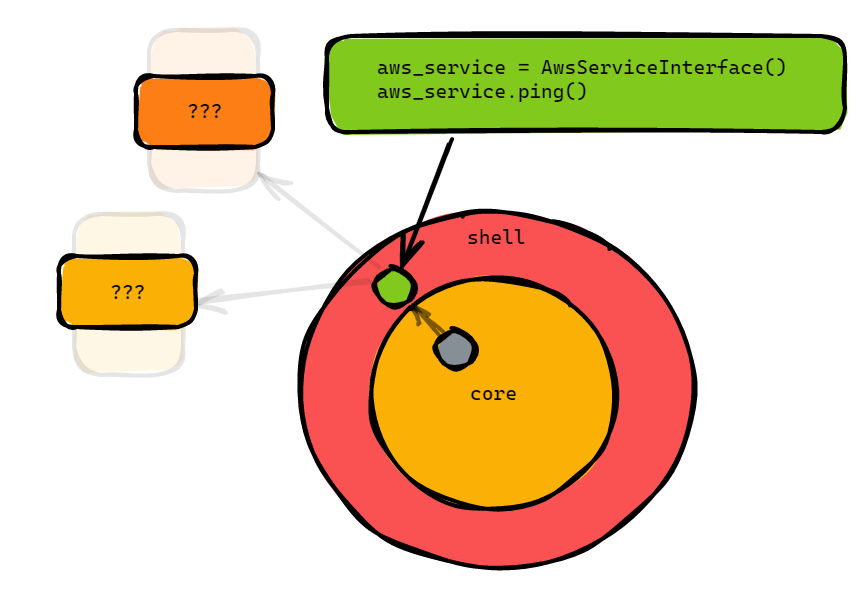
All that it knows is the interface that is implemented, AwsServiceInterface and the functions defined in the interface.
Now you should be able to understand it a bit better when people say profound things like: “depend on abstractions and not on implementations”. You can say “mmm mmmm” and mumble in agreement because you are enlightened too now.
Just because I enjoy talking about this so much, let me repeat myself. We now know what we mean by talking in terms of interfaces. We now depend on an abstraction (the interface, green) instead of the implementation (real or fake implementation, yellow/orange).
Remember Depend on abstractions, not implementations
[1] The final picture is not completely accurate, but you get the point, at test time we use the one, at run time we use the other



Comments