
Leetcode problem 378 First unique character in a string
In this blogpost I tackle Leetcode problem 378 on finding the first unique character in a string.

The problem
The problem is defined as follows:
Given a string, find the first non-repeating character in it and return it’s index. If it doesn’t exist, return -1.
With some example input and output
s = "leetcode"
return 0.
s = "loveleetcode",
return 2.
General strategy
I first tried to go with a brute force strategy, but intuitively already felt the need for a hashmap type of solution.
I found out that getting the brute force algorithm to work was too much effort and the hashmap solution that I intuited turned out to be very quick and elegant.
Brute force solution
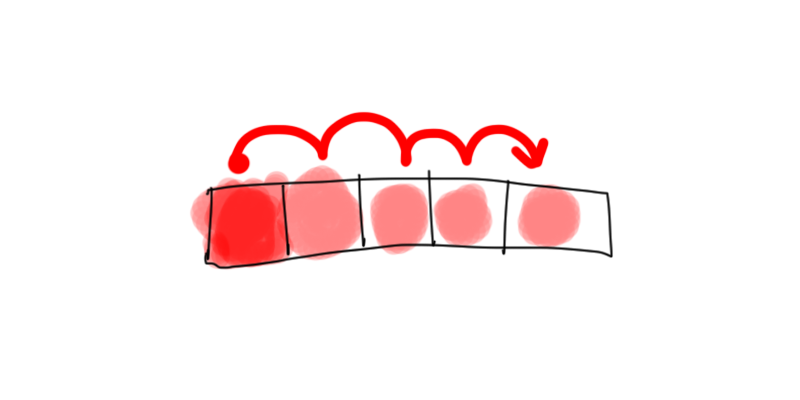
In pseudocode:
- Start at the beginning and take the character
- Loop for every other character in the array and check if it is the same
- If character is not the same, it is unique, return index
- If character is the same, go to next
This was my first solution
def firstUniqChar(: str) -> int:
for i in range(len(s)-1):
unique = True
for j in range(i+1, len(s)):
# loop through all other characters
# if character is no match for all of them we found a unique one
# if character does match, not unique, continue with next
# print(f"Comparing {s[i]} with {s[j]} ")
if s[i] == s[j]:
unique = False
if unique == True:
return i
# No unique chars found
return -1
This failed on a test case with a single character input, say z which shouldve returned 0 of course. We can fix this with a simple rule:
def firstUniqChar(s: str) -> int:
if len(s)==1:
return 0
for i in range(len(s)-1):
unique = True
for j in range(i+1, len(s)):
# loop through all other characters
# if character is no match for all of them we found a unique one
# if character does match, not unique, continue with next
print(f"Comparing {s[i]} with {s[j]} ")
if s[i] == s[j]:
unique = False
if unique == True:
return i
# No unique chars found
return -1
This fails on another test case aadadaad, this is because it does not keep track that the a is already seen. We make another list that we call seen and keep track of the things we’ve seen already. Darned, this also fails on another test case:
def firstUniqChar(s: str) -> int:
seen = []
if len(s)==1:
return 0
for i in range(len(s)-1):
unique = True
for j in range(i+1, len(s)):
# loop through all other characters
# if character is no match for all of them we found a unique one
# if character does match, not unique, continue with next
print(f"Comparing {s[i]} with {s[j]} ")
if s[i] == s[j] or s[i] in seen:
unique = False
seen.append(s[i])
if unique == True:
return i
# No unique chars found
return -1
This one fails on the test case where the unique character is the last one.
At this point I was almost willing to give up the brute force solution. It turned out to be significantly more difficult than I expected. I decided to throw my whole solution out and started with a blank slate.
def firstUniqChar(s: str) -> int:
# Edge case s is single character
if len(s) == 1:
return 0
seen = []
for i in range(len(s)):
unique = True
# Edge case where last char is unique one
if i==len(s)-1:
if s[i] in seen:
return -1
if s[i] not in seen:
return i
for j in range(i+1, len(s)):
# print(i, j, s[i])
if s[i] == s[j] or s[i] in seen:
unique = False
seen.append(s[i])
if unique == True:
return i
# No unique chars found
return -1
I built this monstrosity and then… it timed out.
It was too slow.
I already realised that my solution would run in quadratic time but didn’t expect it to actually timeout. Oh well, on to the hashmap solution then.
Hashmap solution
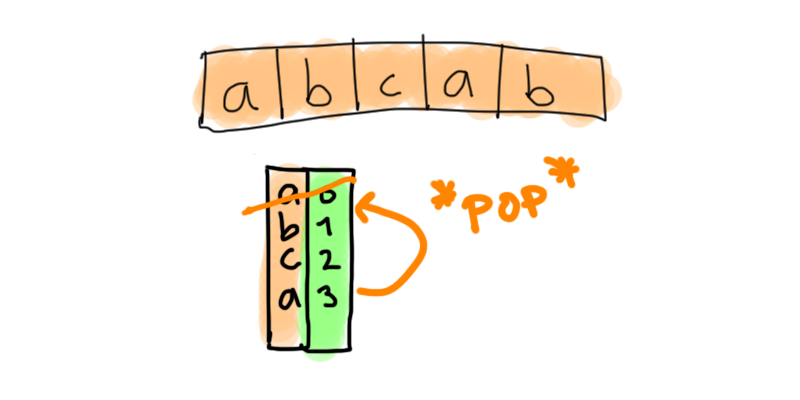
To solve this problem we use a so-called hashmap.
The basic idea is to go through the whole string once and to keep track (in a hashmap/dictionary) the things we’ve seen already.
def firstUniqChar(s: str) -> int:
seen = []
saved = {}
i = 0
for c in s:
if c in seen:
saved.pop(c, None)
else:
saved[c] = i
seen.append(c)
i = i+1
# Return smallest index or return -1 if no unique
if saved:
return min(saved.items(), key=lambda x: x[1])[1]
else:
return -1
In pseudocode:
- Keep track a list of seen characters
seen = ['a', 'b', ...] - Keep track of uniques
saved = {'a': 1, ...} - Loop through string once:
- If we see a duplicate, remove from
saved - If we see a new character, save it in
saved - Update
seen
- If we see a duplicate, remove from
- Once done, return either smallest index in
savedor-1ifsavedis empty
Quick, elegant, concise.
Lessons learned
Getting the solution right took me longer than expected, it took me a solid morning to get this question right. This just shows how untrained and unprepared my brain is for these challenges, hopefully I can improve in the future.
Two main lessons:
- Lesson 1. The hashmap is a super powerful generalisation. Keep your eye open for problems that you can solve using a hashmap type of solution.
- Lesson 2. Do not forget about edge cases. Especially in the brute force one I had to hardcode many edge cases. Annoying, but a necessary part of programming.



Comments